Video prediction
- Action-Conditional Video Predictions article
- Unsupervised Learning of Video Representations using LSTMs article
- Deep predictive coding networks for video prediction and unsupervised learning article
- Hierarchical Long-term Video Prediction without Supervision article
GAN
- Generating Videos with Scene Dynamics article(VGAN)
- Adversarial Video Generation on Complex Datasets article(DVD-GAN)
Generative Temporal Models
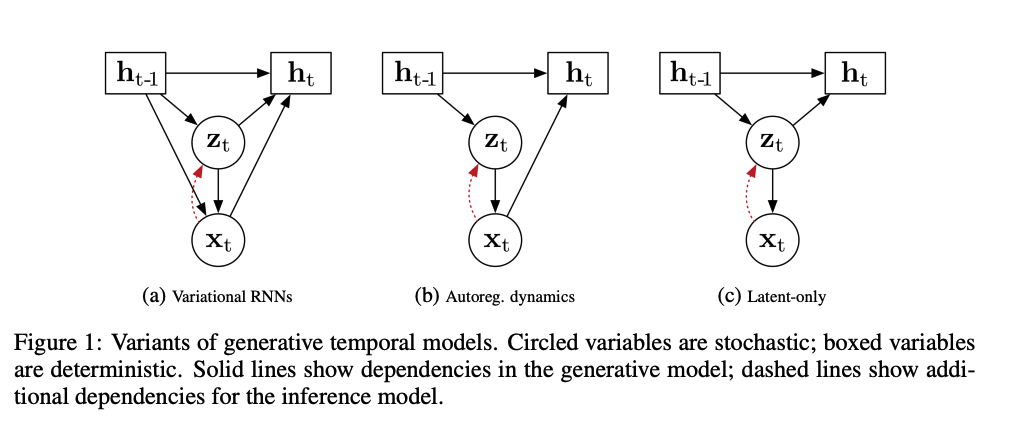
Variational RNNs
- A Recurrent Latent Variable Model for Sequential Data article
- Generative Temporal Models with (external) Memory article
- Improved Conditional VRNNs for Video Prediction article
- hierarchical
Autoregressive dynamics
- feed back predicted images during prediction
- computationally expensive
- strongly tie frame synthesis and temporal models
- distributional shift (during training the input images come from the dataset) article
Autoregressive in space and time:
Autoregressive in time, latent variable for space:
(pixels of each image can be predicted in parallel)
- Stochastic Variational Video Prediction article (SV2P)
- Stochastic Video Generation with a Learned Prior article (SVG-LP)
- Stochastic Adversarial Video Prediction article(SAVP)
Latent dynamics
- = State-space models
- predict a sequence of latent states forward then decode into the video
- learn all dependencies via latent variables without autoregressive conditioning
- no need to feed back images -> efficiency
- early examples: Kalman filters articlevideo, Markovian models article
![[/assets/latent_dynamics.png]]
- Deep Kalman filters article
- counterfactual inference
- Deep Variational Bayes filters article
- Learning Latent Dynamics for Planning from Pixels article(RSSM)
- Stochastic Latent Residual Video Prediction articlecode(SLRVP)
- residual: ODE Euler discretization
- content variable: disentangling dynamics and content
-
Videoflow: A conditional flow-based model for stochastic video generation article
- hierarchical latents:
- learn to separate high-level details from low-level details
- temporally abstract latent dynamics models:
- predict learned features at a slower frequency than the input sequence
- VTVAE two levels the fast states decide when the slow states tick
- Temporal Difference VAE jumpy predictions, without a hierarchy
- VDSM: Unsupervised Video Disentanglement with State-Space Modeling and Deep Mixtures of Experts link
- uses inductive bias (architecture) to learn disentangled representations
- both a varying and constant variable over the sequence
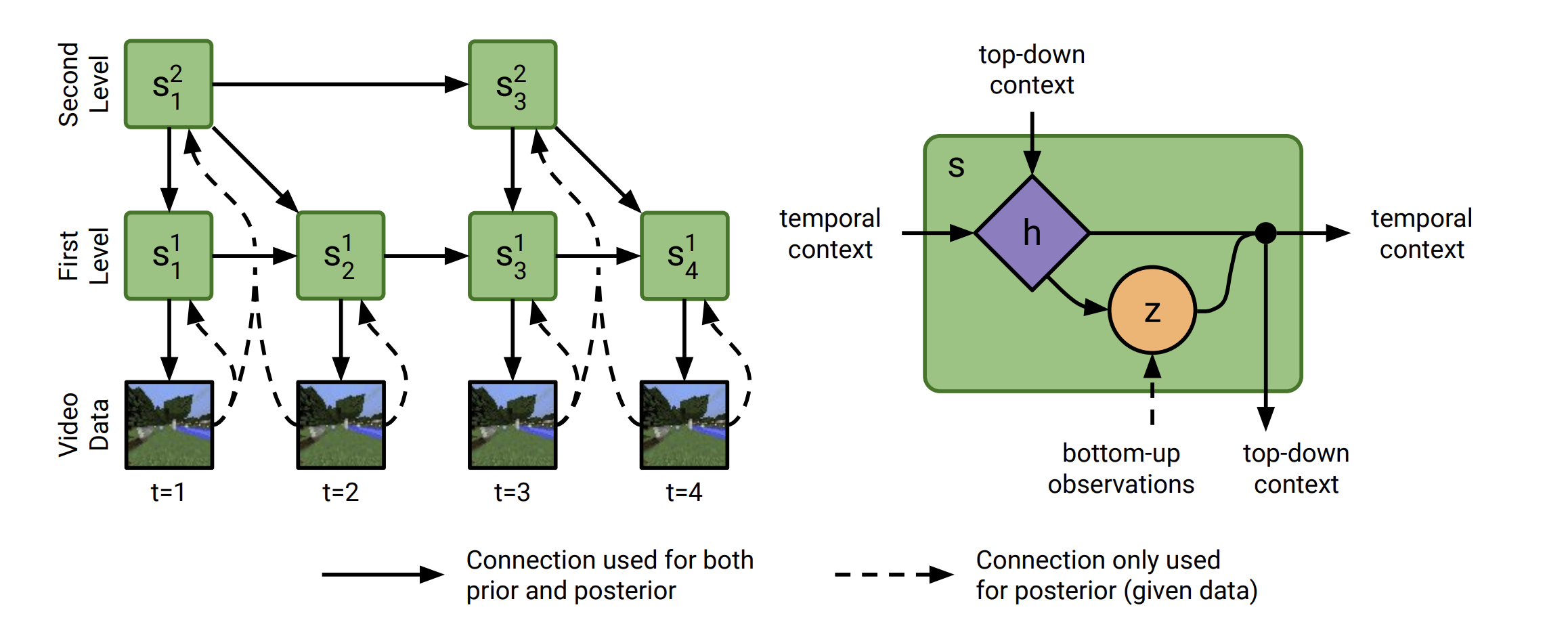
- Clockwork Variational Autoencoder articlecode
- hierarchy of latent sequences, where higher levels tick at slower intervals
- accurate long-term predictions
- automatically adapts to the frame rate of the dataset
- slower levels represent content that changes more slowly in the input, such as the wall colors of a maze, while faster levels represent faster changing concepts, such as the camera position
- Dynamic Predictive Coding: A New Model of Hierarchical Sequence Learning and Prediction in the Cortex link
- The Sparse Manifold Transform linkvideo
-
Minimalistic Unsupervised Learning with the Sparse Manifold Transform link
- Structured State-space models (S4) videoannotatedarticle
Sparse Manifold Transform
- sparse coding: unsupervised learning algorithm video
-
- manifold transform (+ slow feature analysis)
- lift the raw signal x into a high-dimensional space by a non-linear sparse feature function f, i.e. α = f(x), where locality and decomposition are respected
- sparse coding/ vector quantization
- variational approach: parameterize a Laplace distribution
- linearly embed the sparse feature α into a low-dimensional space
- td-vae
- konvolucioval
- gabor filterek?