Reservoir Computing
- review article link
- biology inspired
- rich network of interconnected neurons
- parts of the brain’s mechanisms are similar to those of reservoirs
- including mixed selectivity
- neuronal oscillations
- foundations:
- related:
- Advantages
- fast training process
- simplicity of implementation
- reduction of computational cost
- no vanishing or exploding gradient problems
- potential for scalability through physical implementations
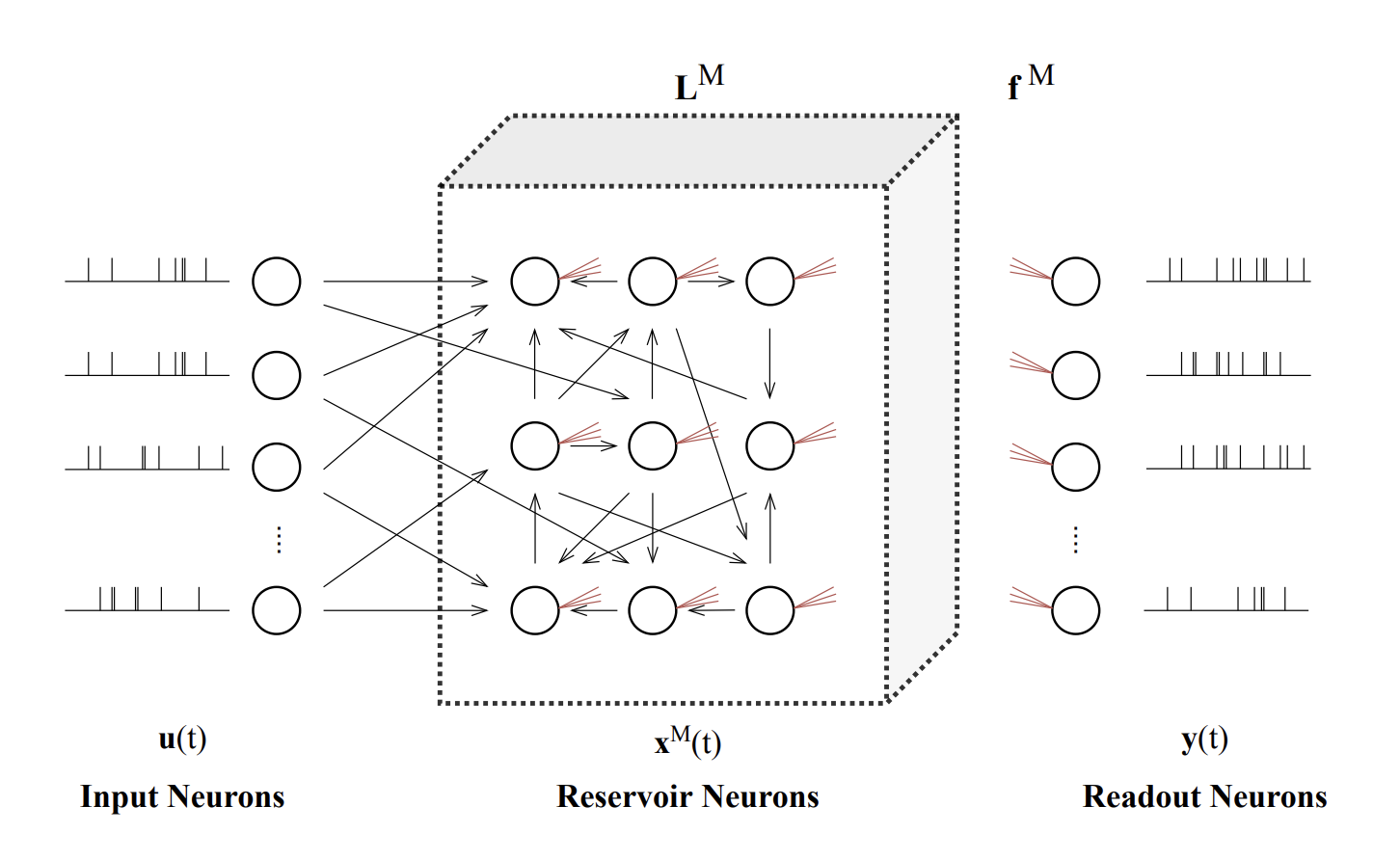
Architecture
Reservoir
- network with randomly connected neurons
- complex and high-dimensional transient responses to input -> state
- weight connections between neurons in the reservoir are usually fixed to their initial random values
Readout
- simple transformation from state to output
- trained by relatively simple learning algorithms
Foundational Approaches
- Echo State Network (ESN)
- leaky-integrated, non-spiking, discrete-time and continuous-value artificial neurons
- standard ESN must meet is the echo state property ESP -> ensure that the network has fading memory
- drawbacks
- fixed randomly initialized weights -> limit performance
- improvement in performance reaches saturation at increased reservoir size
- many variants to enhance performance
- multi-reservoir ESNs, multi-layered ESNs
- parallel reservoir computing
- Liquid State Machine (LSM)
- study the brain mechanisms and model the neural microcircuits
- based on the Spiking Neural Networks (SNNs) with recurrent reservoir structures
- separation property (SP) and approximation property (AP) -> fading memory
Training
- Linear Regression -> Ridge Regression
- sufficient, easy, fast-to-train
- Least Mean Squares (LMS) and Recursive Least Squares (RLS) Methods
- online learning
- LMS: gradient-based error minimization
- might be unstable, struggles to capture the history-dependent temporal data
- RLS:
- more robust, faster convergence
- more computationally costly
- FORCE learning
- most popular online learning method of RC
- suppress the output errors-> aim is not to reduce errors but to keep the errors small
- frequently adapt the weight matrices in the reservoir or readout
- biological/computational neuroscience
- disadvantages:
- trained network too complex to analyze
- require many more units to match performance of gradient based nets
- many adaptations to overcome these
- article link
- Gradient Based
- non-spiking only
- BPDC, BPPT, ACTRNN
- Evolutionary Learning Techniques
- Hebbian learning and Spike-timing-dependent plasticity
- spiking networks
Recent Approaches
Deep ESN
- ESN with multiple reservoirs
- hierarchical timescale representation
- multiple frequency representation, where progressively higher layers focus on progressively lower frequencies
- Deep Fuzzy ESN:
- two reservoirs are stacked
- the first reservoir is applied for feature extraction and dimensional reduction
- the second one is used for feature reinforcement based on fuzzy clustering.
- input samples are clustered more easily
Evolutionary ESM
- Multi-layered echo state network autoencoder
Dynamical System Modeling
Hardware-based Solutions
- realize the reservoir by hardware
- crazy ideas
Next-Generation Reservoir Computing
- RC can be realized as a general, universal approximator of dynamical systems
- the RNN part contains non-linear activation neurons
- the readout layer is a weighted linear sum of the reservoir states
- new concept: linear activation of neurons followed by a non-linear readout is equivalent
- mathematically identical to a non-linear vector autoregression (NVAR) machine
- next-generation reservoir computing (NG-RC)
- no random matrices
- less parameters -> requires only a small number of sample
- less hyperparameters
- faster computational time
- create a digital twin for dynamical systems
- article link